针对每一种基本类型的 Buffer ,NIO 又根据 Buffer 背后的数据存储内存不同分为了:HeapBuffer,DirectBuffer,MappedBuffer。
HeapBuffer 顾名思义它背后的存储内存是在 JVM 堆中分配,在堆中分配一个数组用来存放 Buffer 中的数据。
public abstract class ByteBuffer
extends Buffer
implements Comparable<ByteBuffer>
{
// Cached array base offset
private static final long ARRAY_BASE_OFFSET = UNSAFE.arrayBaseOffset(byte[].class);
// These fields are declared here rather than in Heap-X-Buffer in order to
// reduce the number of virtual method invocations needed to access these
// values, which is especially costly when coding small buffers.
//
// 在堆中使用一个数组存放Buffer数据
final byte[] hb; // Non-null only for heap buffers
}DirectBuffer 背后的存储内存是在堆外内存中分配,MappedBuffer 是通过内存文件映射将文件中的内容直接映射到堆外内存中,其本质也是一个 DirectBuffer 。
由于 DirectBuffer 和 MappedBuffer 背后的存储内存是在堆外内存中分配,不受 JVM 管理,所以不能用一个 Java 基本类型的数组表示,而是直接记录这段堆外内存的起始地址。
public abstract class Buffer {
...
// Used by heap byte buffers or direct buffers with Unsafe access
// For heap byte buffers this field will be the address relative to the
// array base address and offset into that array. The address might
// not align on a word boundary for slices, nor align at a long word
// (8 byte) boundary for byte[] allocations on 32-bit systems.
// For direct buffers it is the start address of the memory region. The
// address might not align on a word boundary for slices, nor when created
// using JNI, see NewDirectByteBuffer(void*, long).
// Should ideally be declared final
// NOTE: hoisted here for speed in JNI GetDirectBufferAddress
// //堆外内存地址
long address;
}用户空间缓冲区:
以给文件写数据为例:
FileChannel fileChannel = new RandomAccessFile(new File("file-read-write.txt"), "rw").getChannel();
ByteBuffer heapByteBuffer = ByteBuffer.allocate(4096);
fileChannel.write(heapByteBuffer);sun.nio.ch.FileChannelImpl#write(java.nio.ByteBuffer)
在 IOUtil 中首先创建一个临时的 DirectByteBuffer,然后将 HeapByteBuffer 中的数据全部拷贝到这个临时的 DirectByteBuffer 中。这个 DirectByteBuffer 就是我们在 IO 系统调用中经常提到的用户空间缓冲区。
随后在 writeFromNativeBuffer 方法中通过 FileDispatcher 触发 JNI 层的 native 方法执行底层系统调用 write 。

而 JDK Buffer 也会根据其背后所依赖的虚拟内存在进程虚拟内存空间中具体所属的虚拟内存区域而演变出 HeapByteBuffer , MappedByteBuffer , DirectByteBuffer 。这三种不同类型 ByteBuffer 的本质区别就是其背后依赖的虚拟内存在 JVM 进程虚拟内存空间中的布局位置不同。
JVM 在操作系统的视角来看其实就是一个普通的进程,内核会根据进程在运行期间所需数据的功能特性不同,而为每一类数据专门开辟出一段虚拟内存区域出来。
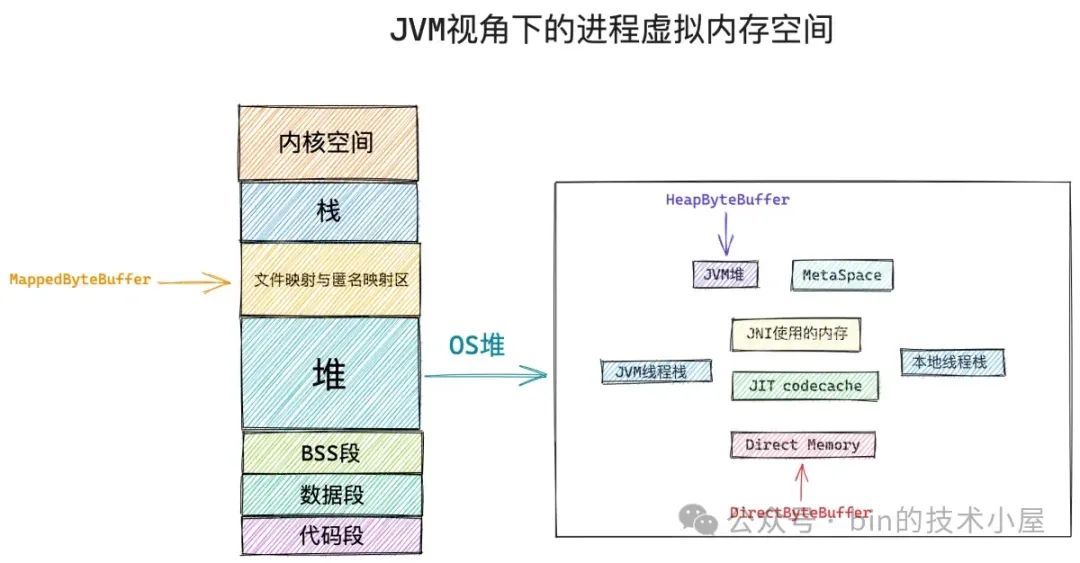
位于 JVM 堆之外的内存其实都可以归属到 DirectByteBuffer 的范畴中。比如,位于 OS 堆之内,JVM 堆之外的 MetaSpace,即时编译(JIT) 之后的 codecache,JVM 线程栈,Native 线程栈,JNI 相关的内存,等等。
JVM 在 OS 堆中划分出的 Direct Memory (上图红色部分)特指受到参数 -XX:MaxDirectMemorySize 限制的直接内存区域,比如通过 ByteBuffer#allocateDirect 申请到的 Direct Memory 容量就会受到该参数的限制。
而通过 Unsafe#allocateMemory 申请到的 Direct Memory 容量则不会受任何 JVM 参数的限制,只会受操作系统本身对进程所使用内存容量的限制。也就是说 Unsafe 类会脱离 JVM 直接向操作系统进行内存申请。
HeapByteBuffer 底层依赖的字节数组背后的内存位于 JVM 堆中:
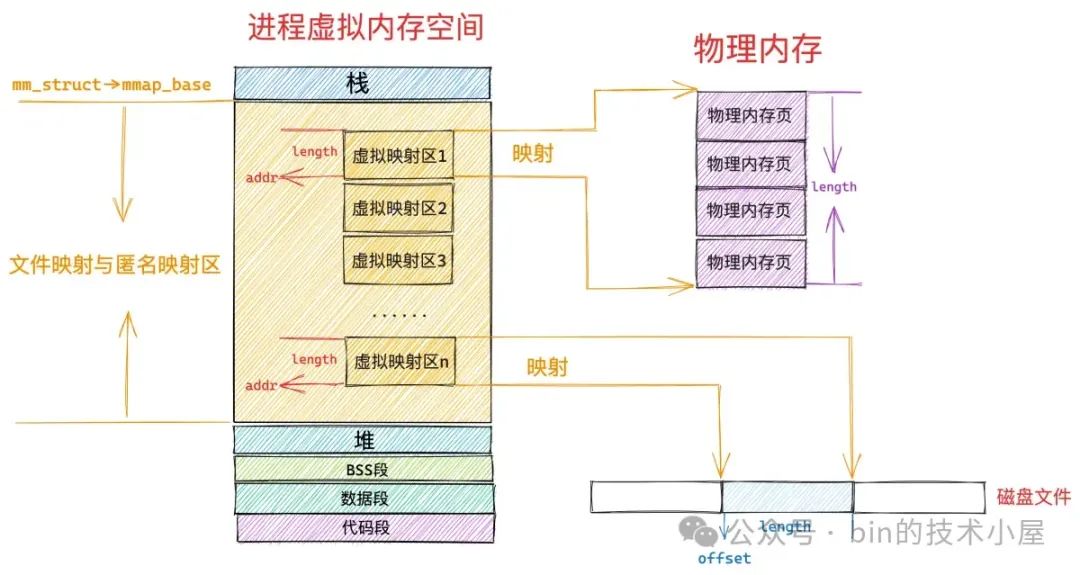
MappedByteBuffer 背后所占用的内存位于 JVM 进程虚拟内存空间中的文件映射与匿名映射区中,系统调用 mmap 映射出来的内存就是在这个区域中划分的。
JDK 仅仅只是对 mmap 文件映射方式进行了封装,所以 MappedByteBuffer 的本质其实是对文件映射与匿名映射区中某一段虚拟映射区域在 JVM 层面上的描述。这段虚拟映射区的起始内存地址 addr 以及映射长度 length 被封装在 MappedByteBuffer 中的 address , capacity 属性中:
mmap:
mmap 有两种映射方式,一种是匿名映射,常用于进程动态的向 OS 申请内存,比如,glibc 库里提供的用于动态申请内存的 malloc 函数,当申请的内存大于 128K 的时候,malloc 就会调用 mmap 采用匿名映射的方式来申请。
另一种就是文件映射,用于将磁盘文件中的某段区域与进程虚拟内存空间中文件映射与匿名映射区里的某段虚拟内存区域进行关联映射。后续我们针对这段映射内存的读写就相当于是对磁盘文件的读写了,整个读写过程没有数据的拷贝,也没有切态的发生(这里特指在完成缺页处理之后)。
当我们调用 mmap 之后,OS 内核只是会为我们分配一段虚拟内存,然后将虚拟内存与磁盘文件进行映射,整个过程都只是在和虚拟内存打交道,并未出现任何物理内存的身影。而这段虚拟内存在 Java 层面就是 MappedByteBuffer。
由于现在我们只是刚刚完成了文件映射,仅仅只是在 JVM 层面得到了一个 MappedByteBuffer,这个 MappedByteBuffer 背后所依赖的虚拟内存就是我们通过 mmap 映射出来的。
此时我们还未对文件进行读写操作,所以该映射文件对应的 page cache 里还是空,没有任何文件页(用于存储文件数据的物理内存页)。而虚拟内存(MappedByteBuffer)与物理内存之间的关联是通过进程页表来完成的,由于此时内核还未对 MappedByteBuffer 分配物理内存,所以 MappedByteBuffer 在 JVM 进程页表中对应的页表项 PTE 还是空的。
当我们开始访问这段 MappedByteBuffer 的时候, CPU 会将 MappedByteBuffer 背后的虚拟内存地址送到 MMU 地址翻译单元中进行地址翻译查找其背后的物理内存地址。
如果 MMU 发现 MappedByteBuffer 在 JVM 进程页表中对应的页表项 PTE 还是空的,这说明 MappedByteBuffer 是刚刚被 mmap 系统调用映射出来的,还没有分配物理内存。
于是 MMU 就会产生缺页中断,随后 JVM 进程切入到内核态,进行缺页处理,为 MappedByteBuffer 分配物理内存。
内核在 do_fault 函数中处理 MappedByteBuffer 缺页的时候,首先会调用 find_get_page 从映射文件的 page cache 中尝试获取文件页,前面已经说了,当 MappedByteBuffer 刚刚被映射出来的时候,映射文件的 page cache 还是空的,没有缓存任何文件页,需要映射到内存的文件内容此时还静静地躺在磁盘上。
当文件页不在 page cache 中,内核则会调用 do_sync_mmap_readahead 来同步预读,这里首先会分配一个物理内存页出来,然后将新分配的内存页加入到 page cache 中,并增加页引用计数。
如果文件页已经缓存在 page cache 中了,则调用 do_async_mmap_readahead 启动异步预读机制,将相邻的若干文件页一起预读进 page cache 中。
随后会通过 address_space_operations (page cache 相关的操作函数集合)中定义的 readpage 激活块设备驱动从磁盘中读取映射的文件内容并填充到 page cache 里的文件页中。
经过 filemap_fault 函数的处理,此时 MappedByteBuffer 背后所映射的文件内容已经加载到 page cache 中了。
后续 JVM 进程在访问这段 MappedByteBuffer 的时候就相当于是直接访问映射文件的 page cache。整个过程是在用户态进行,不需要切态。
不需要切态说明:
后面 JVM 进程对 MappedByteBuffer 的读写就相当于是直接读写 page cache 了,关于这一点,很多读者朋友会有这样的疑问:page cache 是内核态的部分,为什么我们通过用户态的 MappedByteBuffer 就可以直接访问内核态的东西了?
这里大家不要被内核态这三个字给唬住了,虽然 page cache 是属于内核部分的,但其本质上还是一块普通的物理内存,想想我们是怎么访问内存的 ? 不就是先有一段虚拟内存,然后在申请一段物理内存,最后通过进程页表将虚拟内存和物理内存映射起来么,进程在访问虚拟内存的时候,通过页表找到其映射的物理内存地址,然后直接通过物理内存地址访问物理内存。
回到我们讨论的内容中,这段虚拟内存不就是 MappedByteBuffer 吗,物理内存就是 page cache 啊,在通过页表映射起来之后,进程在通过 MappedByteBuffer 访问 page cache 的过程就和访问普通内存的过程是一模一样的。
也正因为 MappedByteBuffer 背后映射的物理内存是内核空间的 page cache,所以它不会消耗任何用户空间的物理内存(JVM 的堆外内存),因此也不会受到 -XX:MaxDirectMemorySize 参数的限制
参考:从 Linux 内核角度探秘 JDK NIO 文件读写本质
从 Linux 内核角度探秘 JDK MappedByteBuffer